

2020年7月1日,第六屆國際權威聲學場景和事件檢測及分類競賽 (Detection andClassification of Acoustic Scenes and Events,DCASE2020) 結果揭曉,北京郵電大學和伟德官网下app官方网站聯合組成的代表隊榮獲自動音頻标注(Automated Audio Caption,Task 6)任務競賽全球第二名的好成績。
此次參賽隊伍由北京郵電大學李聖辰,安徽大學年福東,伟德官网下app官方网站邵曦三位老師共同指導,參賽隊員為北郵的吳雨松同學和陳堃同學,南郵的王子嶽同學和張暄同學。這是他們首次參加自動音頻标注(Task 6)任務競賽,也是南北二郵首次攜手參加聲學場景和事件檢測及分類競賽。
DCASE 挑戰賽是由倫敦瑪麗女王大學(Queen Mary University ofLondon)在2013年首次發起的聲學場景識别挑戰,後續由坦佩雷理工大學(Tamper University of Technology)持續發起,近些年引起了國内外衆多尖端聲學研究界的廣泛關注。本次比賽吸引了亞馬遜,三星電子,IBM,日本電信電話NTT集團等知名企業和清華大學,霍普金斯大學,南洋理工大學等國内外知名高校的衆多隊伍參加。
本次T6組的自動音頻标注任務,需要使用自由文本對一般音頻内容進行描述。這是一個多模态翻譯任務,系統接收一個音頻信号作為輸入并輸出該信号的文本描述,它可以建模概念(如,低沉的聲音),物體(如一輛大汽車的聲音)和環境(如人們在小而空的房間裡談話的聲音)的物理特性,以及高層次的知識(如一個時鐘響了三次)。
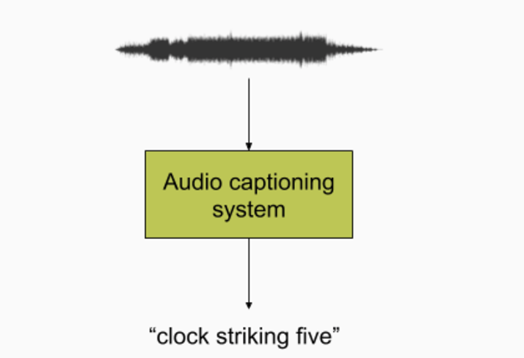
圖一:自動音頻标注系統的過程圖示
此次比賽,該組提出了一個序列到序列模型,該模型由CNN作為編碼器,Transformer作為解碼器。在該模型中,首先對編碼器和詞嵌入進行預訓練,在訓練過程中應用正則化和數據增強技術,并在訓練後進行微調。相比傳統基于LSTM的基準方法,可以更好的生成對于音頻的描述。在比賽規則禁止使用外部數據與預訓練的約束下,該組提出的方案解決了由于數據有限,直接從頭端到端訓練的模型對于聲學事件和語言建模較差的情況,從而可以更好地進行聲音事件和語言的建模。

圖二:模型概述圖
如圖所示,編碼器提取輸入對數梅爾譜圖的特征向量序列,解碼器在處理特征序列時生成每個單詞。首先對編碼器進行多标簽預測的預訓練的任務,在訓練後進行微調。圖中所示的CNN編碼器在訓練前、訓練期間保持相同的架構和微調。最終,該模型在音頻标注性能方面在參賽的11支隊伍中脫穎而出,獲得本次挑戰的第二名。